Buffer Memory Pools in .NET
System.Buffers is a relatively new addition to C# ecosystem. It's one of the helper parts for .NET runtime to improve your work with memory. It's not a language feature, not it's a part of a specific runtime, but was invented by .NET Team as a standalone NuGet Package you can add to your existing applications, whether they're targeting a classic .NET Runtime, or the newer shiny .NET Core.
The idea behind this library is to optimise memory allocation of arrays.
Why is this so important?
To be honest, if you don't care about performance, you should avoid it. This package is only useful for application developers that are trying to squeeze out the last bit of performance from .NET Runtime. And .NET Runtime has some issues, just like any other. This package is about solving issues with arrays.
But first, a little bit of a background around .NET Garbage Collection system.
In general, when you allocate an object on a heap i.e. var array = new int[20], use it for some time and leave unused, it's processed by Garbage Collector (GC). GC is divided in generations, numbered from 1 to 4.
- Generation 0 is the youngest one and contains short-lived objects. Everything by default goes to this generation, unless it's a special case (continue reading). Most of the objects you create end up on G0 and get collected by GC, never going further. GC process on this generation is destroying objects extremely fast and is generally not a performance issue, unless you have plenty of objects. It's also non-concurrent for the reason it's fast. Generally if you software is designed in a way that all of the objects are collected from G0, you are extremely lucky.
- Generation 1 is sort of a buffer between G0 and G2, the objects are placed here if they survive G0 collection.
- Generation 2 contains long-lived objects, for instance a server application with static variables that live for the duration of the process lifetime. You need this generation so that GC doesn't try to continuously collect objects from G0, because it would be a pointless waste of time.
The fourth generation doesn't actually exist, but often referred to as. It's called a Large Object Heap. It's only there to optimise the garbage collection process and here is how it works.
When you are allocating a large object in one go, like a huge array, it doesn't actually go to G0 but rather straight to LOH. This is for a few reasons. The first one is that most probably a large object will be used for a long time, therefore it would be a performance penalty to keep it transitioning over generations to get finally collected. Also collecting a large object takes considerably long time, which is not exactly suitable for G0 running really frequent in non-concurrent manner. A large object is considered anything larger than 85'000 bytes. Why this number? It's mostly imperical and was chosen by .NET team based on various experiments.
But the main reason why arrays that go to LOH cause performance problem is that in order to remove them from LOH, GC needs to:
- Scan for empty space in memory to find out which parts of it is unused. Considering LOH holds large objects this is very time consuming.
- Defragment memory so that large objects are continuous - this is required to free up continuous blocks of memory so that your program can query more when required (remember that arrays always need continuous blocks of memory, then never span in address space). Moving large blocks of memory is also expensive.
Having said that, processing LOH is a long and expensive process, and definitely will slow down your machine, the more large objects you allocate.
Here are a few lnks if you would like to dig deeper in your own time:
- Understanding Garbage Collection in .NET
- Garbage Collection section on Microsoft Docs website.
Allocating Arrays
Array allocation is also an expensive operation. In addition to the overhead of finding an available space in memory to fit the required array, and potentially run LOH defragmentation if the system can't find one, arrays needs to be cleared before you use them. This is mostly for security purposes, as you might get a chunk of memory from another process that contains sensitive data. Memory allocation is actually performed by the OS itself (.NET runtime asks for it). If it takes 2 CPU cycles to clear one byte, it takes 170'000 cycles to clear the smallest large object. Clearing the memory of a 16MB object on a 2GHz machine takes approximately 16ms. That's a rather large cost.
Regarding the .NET runtime, if arrays contain reference types, then during GC they need to be walked through to check for references too. This process is even slower.
What's the Solution
Unfortunately, there is no universal solution to this problem. There are no frameworks or algorithms that can solve this for you. Even if there would be, they need to be smart and therefore also consume CPU cycles which is not what we want.
In general, most people these days wouldn't care about performance, unless you are writing a serious application. Enterprise software developers, big data engineers/scientist or suits simply won't ever hit this problem. However, there are many applications that do care about it and it actually makes a huge business case to optimise for performance. Gaining even 1% of speed boost can save you a lot of money when you're running an expensive distributed system.
If you are going in this direction, Microsoft has recently released a helper package and [some documentation]((https://docs.microsoft.com/en-us/dotnet/api/system.buffers?view=netcore-2.1) on it. You want to use array pooling on relatively large arrays,
System.Buffers to the Rescue
The main problem solved by this package is optimising array allocations. Instead of allocating an array from the runtime, you can "rent" it and return when you're not using it anymore. This way your array can be used again if it's size is suitable.
The staring point to using array pools is the ArrayPool<T> class where T indicates array element type. And to rent an array you could write something like this:
ArrayPool<byte> pool = ArrayPool<byte>.Shared; //obtain a default instance of array pool
byte[] newArray = pool.Rent(100); //get an array of 100 elements
The first line here is getting an instance of array pool. You can create your own pools, however a shared pool is provided for convenience, and in most situations you won't need to create your custom ones.
The second like is asking for an array of 100 elements, and array pool will return it from the pool if it's available, or create a new one if not. In either case it will try to do the best. Note that the pool may actually return a larger size array, if it's available in the pool (usually you will almost always get a larger size) so you have to cater for those situations in your code.
When you're done with the array, you should return it to the pool:
pool.Return(newArray);
Once that's done, the array can be reused either by your code or another library that is using System.Buffers package in the current process.
A Note on performance
Should you always use array pools? Well, as always it depends. In order to guide you to the decision let's compare the performance implications of array allocation vs pooling. I will be using benchmarkdotnet.org benchmarking library and create the following benchmark to investigate the issue:
[ClrJob]
[MinColumn, MaxColumn, MeanColumn, MedianColumn]
[MemoryDiagnoser]
public class PoolingVsAllocating
{
private ArrayPool<byte> _pool = ArrayPool<byte>.Shared;
[Params(20, 100, 1000, 10000, 100000)]
public int N;
[Benchmark]
public byte[] Rent()
{
byte[] rented = _pool.Rent(N);
_pool.Return(rented);
return rented;
}
[Benchmark]
public byte[] Allocate() => new byte[N];
}
The benchmark produces a very interesting result:
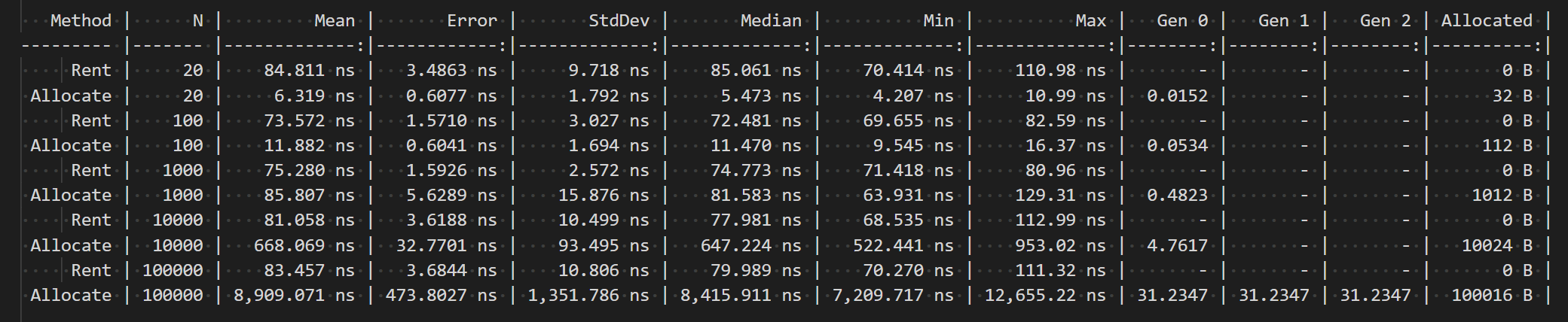
- For small objects like 20 bytes, renting is over 5 times slower than allocating a new array. There is also no pressure on Gen 1 or Gen 2 either, therefore this makes your program much slower!
- Same goes for larger sizes or relatively small objects of 100b, 1000b and 10'000b. However, renting is progressively taking less time than allocating a new object. Even for 1000b renting takes 2ns and allocation is 15ns, therefore you can see some sense in using rented arrays. There is still no pressure on GC, however.
- When testing on 100'000b array, the speed difference is dramatic. Renting is about 125 times faster than allocating an array. There is also 31k going to Gen2 (same as LOH in this example) which will slow down your software even further!
Therefore the answer is again "it depends". Should you always use array pooling? No, because it may actually slow down your code for small objects as shown in this benchmark. Ideally, you would take the best guess and use pooling for pieces of code where you definitely know the objects will be large. And don't forget to add telemetry to your process to actually understand what's the implications of your changes. Having benchmarking embedded into your Continuous Integration process will also help a lot, as you can configure warning signals whenever something goes over a threshold.
Debugging GC
There are several ways to understand GC performance:
- benchmarkdotnet.org is free and awesome library which is perfect for testing small isolated pieces of code and also making performance testing a part of your Continuous Integration process.
- If you are a Visual Studio Enterprise subscriber, you can use the amazing profiling tools built into the IDE itself. They are usually better than competitors, however Enterprise license is costly (and well worth it).
- Otherwise look at the alternative options from Microsoft itself.
- JetBrains provides a worthy profiler for .NET.
- Also RedGate Profilers are an amazing addition to your toolbox.
And of course you can hire me to solve your performance problems ;)
Thanks for reading. If you would like to follow up with future posts please subscribe to my rss feed and/or follow me on twitter.